データのハンドリングを考える
Table of Contents
どうして使いたくもない Word を使わなければいけないのか? どうして不便で計算も不正確な Excel でファイルを作らなければいけないのか? そんな疑問は以前からありました。
すでに業務のデファクトとしてこれらが存在している場合、デファクトを覆すのは非常に困難です。でも、案外みんな「なんか不便な気が」しているようです。今回はその辺を、全体的なワークフローという観点から刺激することを考えてみました。(2003-05)
脱ワープロの情報活用サイクル
データ、まぁ情報という呼び方でも何でもいいんだけど、これを扱うときに、PC という不便な道具の古い発想に縛られちゃーだめです。現在、我々はパソコンの電源を入れてやにわにキーボードを叩き続け、できあがった文書を印刷して保存する、なんて流れでは仕事しません。それはフロッピー1枚も高価だった、ワープロ専用機全盛の昔の話です。下の図で言うと、[作成] → [出力] に一直線に突き進む形のものは間違っても情報処理とは言わないでしょう。
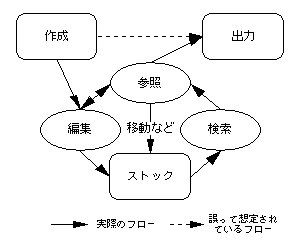
ここで言うワープロはあくまでワープロ専用時代的な、という意味で、ワープロというアプリケーションには限りません。表計算だろうがプレゼンだろうが何にでも当てはまります。
情報の入り口と出口は目立つだけで稀なイベント
いちばん重要なのは編集を中心としたサイクルの部分でしょう。ほんとにまっさらの状態から何かを作り始めるなんて、効率悪いったらありゃしない。上手に過去の資産を活かしながら切った貼ったの加工の段階が長いのです。[ストック] されている情報の中から必要なものを [検索] し、その中身を参照して利用価値を判断し、[編集] を行う。推敲をくり返し、完成したら [出力] します。
[作成] や [出力] というのは言ってみれば情報処理のサイクルの中には入っていない、特殊なイベントなのです。
個々のフェーズで考える
作成 - 「ファイル」という呪縛からの脱却
PC の操作を人に教えるとき、いちばん初めに気を使うのはやはりファイルとフォルダという概念、そしてフォルダの階層構造です。個々のアプリケーションの操作も大事ですが、これが理解できないと、まず使いものになりません。
しかし私たちは実際に何らかの情報を扱うときに、[ ファイル ] → [ 新規作成 ] なんて面倒な手順は踏みません。例えばメモを取るなら紙と鉛筆を手にして書く。これです。このときこのメモに意味のある名前をつけることは可能でしょうか? 「○○についてのメモ」「○月○日○時○分○○さん宛て電話用件メモ」でしょうか? 面倒くさすぎますね。
そこで多くのメモツールでは以下のようなアプローチを取ります
メモ専用のソフト
- ファイル名を取っ払う
- そのソフトを立ち上げている間は、自由にファイルを意識せずにメモを取れる
- 最初にどこに保存するのか指定する場合もあるし、指定できない場合もある
- そのメモソフトを立ち上げていないとメモが再利用できない場合もある
エディタのメモマクロ
- マクロの実行と同時にメモ専用の状態になり、やはりファイル名を意識せずに済む
- ChangeLogMemo とか。著名なエディタにはけっこうあるでしょう
ま、要するに何かをし始めるときにいちいち [ファイル] → [新規作成] なんてやらずに済むってことです。
ファイルを意識しない、「見たまま」のツクリ
Apple の iApps は徹底的にこういう方向に行ってますね。iPhoto も iTunes もファイルの存在を意識することなく、アプリケーションの操作のみに集中できます。実に Mac らしい方法です。
付箋なんかもこの類でしょう。ただし、付箋の場合はデスクトップ領域という制限がありますので、無尽蔵にメモすることはできません。まぁ、その分無意味なメモは減るかもしれない、と思いますが、個人的には付箋はどうしても乱雑になっておしまい、という印象を拭えません(^^; どうにもうまく使いこなせないのです。
ファイルではなく ID であるという捉え方
データベースとかグループェア系だとこれですね。一つ一つの情報に ID を付ける。当然 ID には規則性を作っておきます。欲を言えばある程度自動的に ID が割り振られるとベスト、ってな具合です。
手早く、再利用しやすい形で情報を作成すること
いずれにしても、作業の開始時点でファイル名だとかなんだとか考えずに済む、余計な作業をせずに済む、ということが根底にくるわけです。
ストック
過去のデータを再利用する場合、作業の出発点はストック段階にあります。だから、ストックするデータは編集しやすいデータ形式、再利用しやすいデータ形式を選ぶことが重要です。取り出してきたデータがまったく編集や加工に適していない形だと、極端な話、閲覧専用ということにもなりかねません。
例えばなぜか写真をわざわざ Word に貼り付けて印刷し、保存しちゃうような人がいますが、これは写真データそのものの再利用が非常にやりにくくなるので望ましくありません。Word に貼り付けた写真は Office アプリにはコピーできますが、他の関係ないアプリにはコピーできないのです。(なんでかは知りませんし、特定のバージョンに存在するバグかもしれません。)ま、HTML 形式で保存してしまえば画像を取り出せるのですが、そんな手間を掛けるのは明らかに効率が悪いですし、言ってみれば裏技みたいなもんです。
別な例を出しましょう。Web 用のイラストを Illustrator で作成し、gif か png に出力したとします。このとき保存するのは gif でも png でもなく ai か eps です。これは誰でも分かるでしょ。
また、形式の選択が適切でも、どこに何を保存したのか分からなくなっちゃー意味がありません。取り出しやすい形で保存されていなければ、活用に至らないわけです。意味のある名前のフォルダを掘って分かりやすい冗長なファイル名で保存しろ、などの方法論はすべてここが出発点になっているわけです。確かに保存の段階で注意すべきことが多いのはいろいろ面倒です。しかし、ここをしっかりさせないと無駄なデータの再加工、再入力などが発生してしまいます。
壮大な無駄は以下のような図が例として挙げられるでしょう。
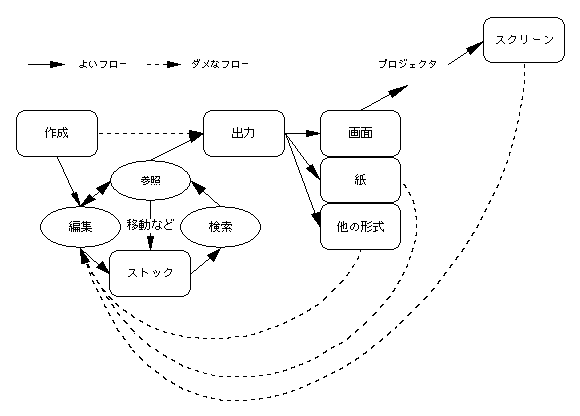
これはかなり最悪です。適切でない形式で保存したので再加工に手間が掛かったり、自分たちで作成したはずなのに元データが見つからないからスキャンして取り込み直したり、スクリーンショットを撮り直したり。これはデータの作成、出力、再編集が比較的短時間の間に起こればまずあり得ない笑い話ですが、数ヶ月から年単位に間隔が空いてしまうと、実はどこでも起こり得ることなのです。特に複数の人間が関係したらその確率は飛躍的に高くなります。ナンセンスなことだと自信をもって笑い飛ばせる人は、実はそれほど多くないんじゃないでしょうか。
検索
いろいろな技術が開発されてはいますが、現在最も有効な検索手段はやはり言葉による検索です。
しかし伝統的な grep 検索は情報に”重み”がなく、引っかかった言葉が果たしてどれくらいそのファイルの中で重要なものかということは判断できません。従来のテキストファイルやワープロ文書では、検索の精度は実はそれほど高くありません。
情報の”重み”を手軽に表現できる形式には HTML があります。が、すべての文書データが HTML になっているってのはかなり稀というかまずあり得ません。CSS を十分に理解していなければ印刷データとして HTML を利用するのはなかなか難しいですし、従来からの”縛られた発想”で、どうしても情報の重みより細かい(でも実はそれほど高度なレベルではない)レイアウトを手で調整することに目が行ってしまいがちです。それに情報の”重み”を意識して HTML 文書を作成してくれるワープロソフトはそれほどポピュラーではありません。
また、人間の記憶は高度な関連付けでもって複雑に絡んだ情報をそのカタマリのまま扱うことができますが、PC 上のデータはそういうわけにいきません。扱うアプリケーションが違えばファイル形式が変わり、それぞれのファイル形式には得意なデータの種類があります。万能のファイル形式、万能のアプリケーションというものは存在しません。
では、複数の種類の情報を一括して扱いたい、複雑な情報、大量の情報を簡便に高速に扱いたいときにはどうすればよいのか。そのために DBMS があります。また DBMS の多くはクライアント・サーバモデルで成り立っているのでネットワークの向こうにデータを保存することができ、多人数のデータを一箇所で扱うことが可能になります。情報は一元管理しなければ確実に破綻します。
しかしそこで、じゃあ Access だ FileMaker だと考えるのはちと早計です。Access でデータベースを組む、それはいいでしょう。でもその結果、Access を使えないと何もできないという状況に陥っては本末転倒なわけです。目的はなんでしょうか。自分たちの再利用しやすいデータを効率的にストックし、検索することだったはずです。これが個人が勝手に Access を使いこなすという程度ならまだよいですが、組織の中や外部とのやりとりにまで影響してしまうようなことは避けなければいけません。定型書式ならデータベースでやっちゃった方が楽じゃん、と考えることは間違いじゃないのですが、それがデータの作成段階まで規定してしまうかどうかは、全体的なワークフローの中で決めなければいけないことなのです。
この部分の効率を上げるには残念ながらそれなりにスキルが必要です。手っ取り早さを求めている場合はこの部分の改善は難しいでしょう。それでも、特殊な形のデータベースのようなものであったり、特定のアプリケーションや画像など、伝統的な検索方法が通用しない部分で検索できるようにするツールなども、探せばあります。例えば画像ならキーワードを登録できるアルバムソフトなんかはこれに当たるでしょう。Namazu 全文検索を使えば文書作成にはとりあえず Office を使って、特定の場所に保管しておけば自動的に検索可能になる、という仕掛けは可能です。こうしたツールと、伝統的なファイル、フォルダの命名規則の合わせ技だけでも、ずいぶんと効率は変わります。
サイクルを意識してよりよい道具を選ぶ
個々の技術、個々のアプリで面白いものはたくさんあります。個々のアプリの習熟度が上がっていくのもまた楽しいです。でも、それはサイクルの中でどういう意味を持っているのかっつーとこなんですよね。これが抜け落ちていたら意味ないんですよ。
特にストックの部分はかなり重要で、データ形式の寿命も意識しておかなくてはいけません。私はアウトラインプロセッサに Kacis Writer Free を利用していて、かなりこれに依存していました。ところが最近配布終了になってしまったのです。(手元にコピーはありますけど。)これも機能面では問題なかったのですが、データ形式としてはイマイチだった、ということになります。まー個人で使っていた(一部周囲の人間にも薦めていたのでその辺はアレですが)程度なのでそれほど大事には至らなかったと思いますが、なんだか反省させられたというか、非常に残念な思いをしております。ま、Kacis ノートを買えば済むっていう話でもあるんですが。
現在(2003-05)私は PukiWiki を日常的にいろんな局面で利用しています。これも PukiWiki の開発はいずれ止まる可能性は十分にあります。まぁ、すべてのアプリにそれは言えるわけですが。でも GPL だし、誰が引き継いでもいいし、いざとなればデータはテキストファイルだからなんとでもなる、という安心感がありますし、実際の作業時にはファイルの存在を意識することはないのでその辺もかなり楽チンです。印刷はどうするんだって? 大丈夫、ちゃんと印刷にも使えます。
もちろんこの解は万人向けではありません。個人で PukiWiki を利用するには自分で Web サーバを起こし、PHP と PukiWiki をセットアップする必要があります。日常的に CGI がどうとか Web の制作がどうとか言う人でない限りはこの環境はヘビーでしょう。同じ理由で自分も MySQL に依存している Wiki は採用しませんでしたし。(普段 MySQL には用ないし、いざというとき MySQL が動いていないとデータを取り出すのが大変だから。)
大事なことは、自分の現在と将来、自分の周辺全体の様子を俯瞰して、サイクルを作り出していくことです。既存の情報処理が上手にサイクルになっていないならなおさらです。どのようにサイクルを設計するか。ここが最も重要なポイントであり、楽しい作業でもあるわけです。