Yet Another Namazu セットアップメモ
前提
まずは確認事項。
- Namazu は GPL 2 に従って配布されている全文検索システムである
- 要するにファイルの中身に対してキーワードで検索を掛けることができるものである
- Namazu での検索のためには事前にインデックスを作成しておく必要がある
- Namazu の動作には Perl が必要
- CGI を使うには Web サーバと適切な設定が必要
- Web サーバの設定はセキュリティを考慮して行なうこと
まず Namazu は Perl を利用するシステムなので Perl がインストールされている必要がある。最近の UNIX では Perl は標準的に入っている(※ FreeBSD 5 のコア部分からは外れるとか?)んだけど、Windows では標準ではないので、自分で ActivePerl を入手してインストールしておくこと。はっきりゆうて昔と違って ActivePerl のインストールなんて誰でもできるのでビビらずにやってください。
ただし、Namazu や kakasi、pdftotext などの今回紹介するプログラムはいずれもインストールシールド形式じゃないので、ダブルクリックでお気楽セットアップじゃなきゃやだん、という人には Namazu のシステムは向かない。悪しからず。
Namazu の検索は Windows 標準の検索のように grep 系のその場でファイルの中身を読み取って検索していくタイプではなく、事前に検索対象ディレクトリについてインデックスを作成するタイプである。したがって namazu を使って実際に検索を行なうには mknmz というプログラムを使ってインデックスを作成しておく必要がある。その代わり検索の実行はかなり速い。要するにこの検索システムに必要なプログラムは2種類あって、
- namazu が検索用コマンド
- mknmz が事前にファイルの内容をインデックス化しておくためのコマンド
である。必要なプログラムは以下から入手されたし。
- Namazu for Win32 --- ここに必要なものへのリンクは用意されている
- kakasi for Win32
- ActivePerl
CGI を利用する場合
ブラウザから検索を実行するためには CGI という枠組みを利用する。当然 Web サーバがインストールされていて、CGI を許可する設定になっていないといけない。
インデックスは Web サーバのドキュメントルート内にある必要はないけど、見つかったファイルをそのままブラウザで見るためには、その見たいファイルがドキュメントルートの下にあるか、Alias を使ってブラウザが見ることのできるディレクトリになっている必要がある。つまり、検索対象とするディレクトリがドキュメントルートの下か Alias で指定したディレクトリの下にある必要がある。
もちろん CGI 動作させなくても Namazu は使えるんだけど、どうせならブラウザから利用できた方が使い勝手がいいし、他のマシンからデータベースを利用するのに便利なのでついでに Web サーバのセットアップもマスターしてしまうとよいでしょう。
ただ。
無防備な Web サーバを立ち上げた場合は自分のディスクの中身が全世界に向けて無防備に配信されまくりというとんでもない事態になったりするので、ちゃんと localhost などの特定のマシンからの接続以外は受け付けないとかユーザー認証を入れるなどの対処をしておくこと。
この辺は Namazu や kakasi のセットアップとは基本的に関係ないので端折る。Web サーバのなんたるかが分かんない場合はそれが分かるようになるまでこの方法は諦めましょう。参考までに Web サーバが Apache の場合は SOFTBANK の BlackBook シリーズなんかがまとまっていてよいと思われる。必要なソフトはこの辺から。
まとめると
けっきょく必要なものは
- コマンドラインからだけしか使わない場合
- kakasi
- namazu
- Perl
- Web ブラウザを使ってサクサク検索したい場合
- Webサーバ(+CGI実行の設定)
- その他
- nkf
- pdftotext
- gzip
- など、必要に応じて
って感じだ。ちなみに私は nkf も gzip もすでにインストール済み、Web サーバのインストールも CGI の実行の設定も Perl のインストールもとっくに済んでいるので、今回新たに必要だったのは namazu と kakasi と pdftotext くらいのものであった。つまり、普通の人がイチから Namazu を使って快適データベース!を始めるよりもかなり楽チンだったということは先に書いておく。
kakasi のインストール
ChaSen は使わなかったので入れたい人はご自由に。
kakasi は KAnji KAna Simple Inverter の略。
漢字かな混じり文をひらがな、カタカナ、ローマ字に変換することを目的にしている。要するに通常のかな漢字変換の逆を行なう。
今回は Namazu が kakasi の辞書を利用するためにインストールするが、単体でも kakasi はなかなか面白く使えるソフトだと思う。(例えば自分の Web の子ども用バージョンを作ってみるとか。辞書を鍛えに鍛えれば少しは点訳が楽になるかもしんない。)
(Win32 バイナリはコンパイル(make)のときに辞書ファイルの場所などを決め打ちで build しているので、)指定ディレクトリ以外に辞書ファイルを持ちたい場合は、環境変数をセットしたり option のあとに指定するようなことがドキュメントには書いてあるんだけど、Win32 版はコマンドラインオプションで指定した辞書ファイルをうまく認識しない(何か失敗しているのか?)ので方法としては
- c:\kakasi に入れるか、
- 環境変数をセットする
のどちらかになる。
環境変数のセットは(NT系システムの場合)ユーザー環境変数、システム環境変数のどちらでもよい。システム環境変数にセットした場合はシステムの再起動が必要。かな。
試しにこんな構成でインストールしたが問題なく動いているようだ。もちろん \usr\local\bin にパスが通してある。DLL は必要なのか?
C:\usr
└─local
├─bin
│ atoc_conv.exe
│ kakasi.exe
│ mkkanwa.exe
│ rdic_conv.exe
│ wx2_conv.exe
├─lib
│ kakasi.dll
│ kakasi.lib
│ libkakasi.a
│ libkakasi.la
│ libkakasi.lib
└─share
└─kakasi
itaijidict
kanwadictNamazu のインストール
インストールは
- 目的のディレクトリへの展開
- 展開したディレクトリでの NMZSETUP.BAT の実行
の二手間で行なう。NMZSETUP.BAT を実行したディレクトリがインストールディレクトリになるので実行の前にディレクトリ構成を固めておく。インストール先の構成は (指定ディレクトリ)\Namazu 以下に入ることを前提にしている。例えば C:\usr\local\Namazu なんて感じ。
これ以外の例えば C:\usr\local\bin\namazu.exe などのようにインストールしたい場合は各設定ファイル、環境変数をそのように書き換える必要が出てくる。面倒を避けたければ kakasi 同様、デフォルトの C:\Namazu に入れるのがよい(なんかかっこ悪くて好きじゃないけど。)
nmzsetup.bat に kakasi の行方を教える
このとき、この nmzsetup.bat バッチファイルの中で kakasi のディレクトリを c:\kakasi に決め打ちしている部分があるので、もし kakasi を c:\kakasi 以外のディレクトリにインストールしていたらこの部分を書き直すこと。43, 44行めにこんなのがある。
if ($dictdir eq '') {
$dictdir = "$homedrive\\kakasi\\share\\kakasi";ここを書き換える。この辺は環境変数をセットするための記述なので、あとで環境変数を手作業で書き直してもよし。好きな方法を選ぶ。
環境変数
セットする環境変数は以下の通り。
| 環境変数 | 内容 |
|---|---|
| ITAIJIDICTPATH | (kakasi の)異体字辞書ファイルの場所 |
| KANWADICTPATH | (kakasi の)漢字かな変換辞書の場所 |
| MKNMZRC | mknmzrc の場所 |
| NAMAZULOCALEDIR | (namazu の利用する) locale 情報の入っている場所 |
| NAMAZURC | namazurc の場所 |
また、rc ファイルの中でそれぞれの動作に関する細かい設定をセットする。
設定ファイル
mknmzrc
mknmzrc は名前のまんま、mknmz のインデックス作成時の動作に関する設定を行なう。
mknmzrc の最後のところの設定でPerl ライブラリ、様々なファイル形式対応するためのフィルタ、CGI 動作時の検索フォームテンプレートなどを納めている場所を教えてあげるので、ここを書き換える。/usr/local/ 以下に bin や share などを直接置きたい、UNIX っぽさが好き、という人はこんな感じにするわけだ。
$LIBDIR = 'C:/usr/local/share/namazu/pl';
$FILTERDIR = 'C:/usr/local/share/namazu/filter';
$TEMPLATEDIR = 'C:/usr/local/share/namazu/template';UNIX っぽさに何の意味があるの?と問われれば、はいごめんなさい、ありません。
インデックスファイルをどこに作成するかを mknmz に教えてやるのは mknmz 実行時のオプションで教える。
namazurc
namazurc は検索するときの動作の設定を行なう。
今度は頭の方で
Index C:\var\Namazu\Indexと、デフォルトのインデックスファイルがどこにあるか指定する場所がある。上のようにしておくと UNIX っぽいかな。
CGI で実行させる場合にはこの設定ファイル namazurc を CGI プログラム(namazu.cgi.exe)と同じディレクトリに置いておく。
実行ファイル
mknmz の中で /namazu 以下に Namazu をインストールしていることを前提にしている記述があるのでそれを修正。47, 48 行目がこんなことに。
my $PKGDATADIR = $ENV{'pkgdatadir'} || "/namazu/share/namazu";
my $CONFDIR = "/namazu/etc/namazu"; # directory where mknmzrc are in.
必要に応じて直す、と。
基本的な使い方は
mknmz -o インデックス作成先ディレクトリ 検索対象ディレクトリ
となっている。Win32 ではこの mknmz はバッチファイルになっているので、例えば最後の方で述べる複数のインデックスを生成するために mknmz をバッチファイルの中から何回も呼ぼうと思った場合、call 文を使わないといけないので注意。
CGI
namazu.cgi.exe を CGI の呼び出しを行いたいディレクトリにコピー。ついでに namazurc を同じディレクトリにコピー。
Replace /c\|/www/ /ブラウザからのアクセス用に Replace を設定しておくこと。そうしておかないとローカルのディスク内でも検索結果からリンクをたどってブラウザに表示することができない。Windows のドライブレターのコロン(:)の部分は上のように \| と書く。
検索ページの HTML は Template ディレクトリにあるので、適宜これを改造する。よくある単語なんかを選択できるようにしておくと親切かも。
| ファイル | 内容 |
|---|---|
| NMZ.head | 検索結果の冒頭部分 |
| NMZ.foot | 検索結果の末尾部分 |
| NMZ.body | 検索式の説明 |
| NMZ.tips | 検索のコツ |
| NMZ.result | 検索結果の表示書式 |
で、使うのが日本語なら(ま、普通そうでしょう)末尾に .ja とついているファイルを編集する。詳細はマニュアルを読む、と。これらのファイルは Perl に通す都合上 EUC になっているので、EUC の扱えるテキストエディタ、HTML エディタを用いること。
フィルタ
ローカルで使う場合は基本的に普通の Web サーバ用途よりも多様なファイルを検索対象にすると予想される。Namazu ではテキストファイル以外(含むHTML)のファイルを扱う場合は、kakasi やインデクサに通す前にフィルタを適用する必要がある。フィルタは Perl スクリプトであり、以下に上げるフィルタが 2.10 では標準で備わっている。(同梱のドキュメントを参照のこと。)あとは、必要に応じてフィルタが要求する外部コマンドを用意してあげればよい。
| フィルタ | 依存コマンド |
|---|---|
| gzip | gzip コマンド or Compress:Zlib モジュール |
| bzip2 | bzip2 コマンド |
| compress | compress コマンド |
| deb | dpkg コマンド |
| dvi | dvi2tty, nkf |
| excel | xlHtml, lv or doccat |
| hnf | Namazu for hns |
| hdml | |
| html | |
| mailnews | |
| man | nroff or groff |
| mhonarc | |
| msword | wvWare, lv or doccat |
| pdftotext | |
| postscript | ps2text |
| powerpoint | pptHtml, lv or doccat |
| rfc | |
| rpm | rpm |
| taro | doccat |
| tex | detex |
| Win32 用フィルタ | 依存コマンド |
| ichitaro456 | jstxt(DOSコマンド) |
| oleexcel | Excel本体 |
| olemsword | Word本体 |
| olepowerpoint | PowerPoint本体 |
| oletaro | Word本体 |
| olertf | Word本体 |
ローカルディスク内の Office データ
上の表を見れば分かる通り、MS Office については作成に使った Office がそのままフィルタから OLE で呼び出されてインデックス作成に貢献してくれる。つまり、自分が MS Office で作ったデータを自分のマシンの中で検索するためには特別なことは何もしなくてもよい、ってことである。いやぁ、実に楽チンだ。この機能を重宝する人はけっこう多いだろう。
ただし、PDF データを検索対象にするためには一工夫が必要である。pdftotext というコマンドが必要になるのだ。入手は以下の URL から行なえる。
Xpdf は X Window System 上でフリーで PDF の表示の行なえるプログラム群なのだが、この中の PDF ファイルを解析したり文字列を抽出する部分は X に限らず様々なプラットフォームで利用可能となっている。pdftotext はその名の通り PDF 内に含まれるテキスト部分を抽出してくれるプログラムだ。
セットアップの方法が英語で書かれているが、要するに
- パスの通ったディレクトリに実行ファイルを置く。
- そのままでは日本語に対応していないので Japanese Support package も入れる。
- JS package の場所は適当でよいが、その情報が正しく pdftotext に伝わるように、pdftotext と同じディレクトリにあるはずの xpdfrc ファイルにその情報を追加する。
追加する情報のサンプルは support package のアーカイブの中に add-to-xpdfrc として書かれているのでそれを参考にすること。
単体で使う場合の注意としてはテキストファイルを書き出すときの文字コードを指定してやらないと日本語部分が全然出てこないということである。つまり、オプションを指定しないと使いものにならないってこと。
Namazu 2.0.10 以前 + xpdf 1.0 以降を使う場合の注意。
pdftotext のコマンドラインオプションが 1.0 から変わっているので、Namazu の filter の pdf.pl を書き換える必要がある。
system("$pdfconvpath -q -eucjp -raw $tmpfile $tmpfile2");
の部分を
system("$pdfconvpath -q -enc EUC-JP -raw $tmpfile $tmpfile2");
のように変更する。ま、この辺は Namazu のバージョンアップでそのうち問題にならなくなるだろうけど。
参考
- namazu for Win32で、xpdf1.00を使う方法
http://plaza6.mbn.or.jp/~sugimoto/tech/xpdf_japanese.html
# ところで gzip が入っていなくてもオッケーなようだが、これはなぜだ?
インデックス作成
インデックスを作成するディレクトリはあらかじめ用意しておかなければいけない。Namazu が自動的に指定されたディレクトリを作成するようなことはない。
インデックスの作成は最初の1回目こそ非常に時間が掛かるが、以降は自動的に更新されているかどうかを判別してくれるので案外速い。(もちろんインデックスを作成するディレクトリに大幅な変更があった場合はこの限りではないが。)
また、「ファイル」のないディレクトリを対象にした場合、その中にサブディレクトリがあってもサブディレクトリを検索してくれない。現時点(2002-06)では対処方法不明。
インデックス作成先に指定されたディレクトリにはインデックスのほかに CGI から利用できる HTML も生成される。(したがって mknmz を実行するときには CGI を利用するかどうかを気にする必要はない。)
インデクシングルール
ローカルディスクの中をインデクシングする場合、ファイルの形式としては対応していてもインデックスを作るまでもないファイル、インデックスに反映しない方が見通しがよくなるファイルがけっこうある。そこでその辺を mknmzrc で設定する。
例えば筆者は Basilisk II を利用しているのでローカルディスクのそこかしこに .finf というディレクトリがあり、この中に各ファイルの MacOS 用の情報が入っているのだけれど、これはインデックスに反映してほしくない。そこで
$EXCLUDE_PATH = "\.finf";
このように設定する。他にも特定のディレクトリを除外したければ | で除外したいディレクトリに一致するような正規表現を追加していけばよい。ファイルの場合は $DENY_FILE に設定する。
もしくは必要なディレクトリだけを列挙して mknmz を必要な回数実行するようにバッチファイルなんかに書けばオッケー。その場合はインデックスの作成場所を細かく変えてやらないと索引情報が矛盾してしまうようだ。これはすぐ下で。
スケジューリング
適当にバッチファイルを作ってスケジュールのタスクに登録すればよいかと。スケジュールを実行する機能のない Windows 95 の場合は、起動時や終了時など適当なタイミングで任意のプログラムを実行できるプログラムをかませるとよい。(ま、でも、Windows 95 じゃ24時間運用は無謀だと思うけど。)
複数のインデックス
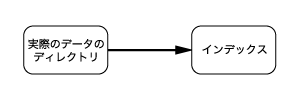
最も基本的な Namazu データベースは図1のように1つのディレクトリ(サブディレクトリも含む)に対し、1つのインデックスを生成するものである。
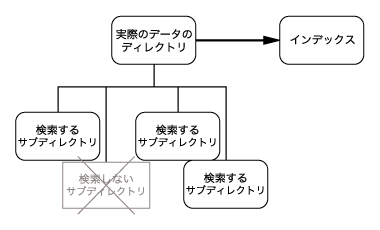
検索対象のディレクトリがいくつかにまたがっている場合、インデックスの生成には二通りの方法がある。
- 上位のディレクトリをインデックス作成時に指定して、必要のないディレクトリを $EXCLUDE_PATH で除外していく
- mknmz をディレクトリの数だけ実行し、複数のインデックスを作成する
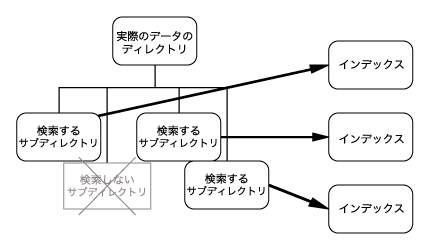
それぞれメリットがあって、
- 検索対象の指定を1つのディレクトリで行なえば、インデックス化したファイル、キーワードの数が簡単に正しくセットされる
- 検索対象のインデックスを複数用意した場合、そのインデックスをユーザーが選択することができる
というところ。1. のやり方は上で触れているのでここでは 2. の複数のインデックスを用意するときの注意点を述べる。
まず、複数のインデックスを一度に生成するためには、一般的には Win32 システムではバッチファイルを用いる。ところがインデックスを生成する mknmz もバッチファイルなので、バッチファイルの中からバッチファイルを呼び出す形になる。このとき、call 文を使って call mknmz という呼び出し方をしないと元のバッチファイルに戻ってこれないので注意。
ディレクトリがいくつかにまたがっているなどして複数のインデックスを作成する場合、インデックス作成先のディレクトリもその分用意する必要がある。複数のディレクトリのインデックスを一箇所に作るとインデックス情報が矛盾するし、lock されていてインデックスが作成されないなどの症状が出る。
複数のディレクトリのインデックスを作成する場合、検索対象ディレクトリ1に対してインデックスディレクトリ1の対応をしっかり取らなければいけない。
またインデックス更新日や文書数、キーワード数はこのインデクシングのときに生成されて、インデックスディレクトリの中の HTML の中に1つずつ埋め込まれる。複数のディレクトリのインデックスを生成した場合はこれらのファイルも複数生成されるのだが、検索フォームの表示に使うファイルはどれか1つを指定しなければいけない。つまり、実際のインデックス情報が複数あるのに表示に使えるファイルは1つだけということになり、そのままでは正しい数値を出力することはできない。どうしても正しい数字を得たい場合はインデックス生成後、スクリプトでテンプレートファイルを修正するなどしなければいけない。面倒ならこの数字の部分を削除してしまうのがよいだろう。